研究紹介:正田 備也 教授
専任教員紹介
2020/07/15
教員
「手元にあるデータをもっと良く知りたい」潜在変数を使ったデータ分析 ~トピックモデルを中心に~
深層学習を中心とした機械学習によるデータ分析は、いまは主に、新たにやって来るデータについてその種類や構造を予測したい、というデータ分析です。手元にあるデータは、ニューラルネットワークなど機械学習のモデルを“賢く”させるために使われます。モデルを十分に“賢く”させた後、新たにやって来るデータをそれに入力し、得られる出力を予測に役立てます。
一方、私が主に取り組みたいデータ分析は、手元にあるデータ自体を良く知ろうとする分析です。
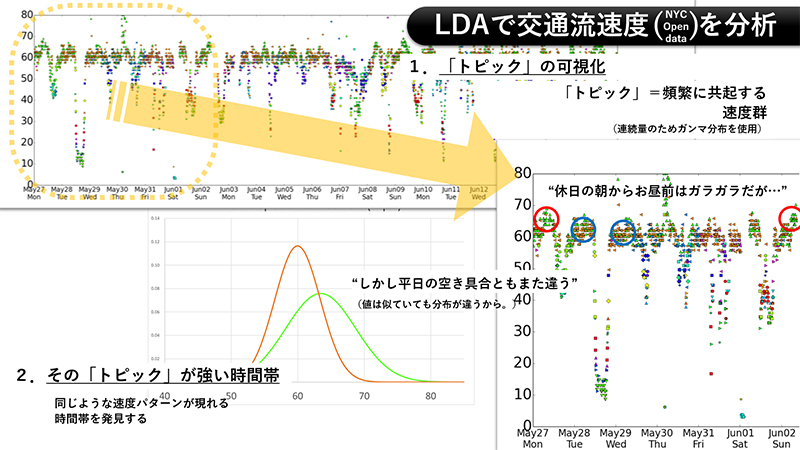
予測のためのデータ分析では、教師あり学習という種類の機械学習の手法がよく使われます。これは、手元にあるデータをモデルへ入力したときにどのような出力が得られると望ましいかを人間が計算機に教え、その通りに出力するようモデルを“賢く”させる手法です。しかし、人間が計算機に教えられるほどデータについてよく分かっていないこともあります。例えば、文書データであれば、あまりに文書数が多いため、一つ一つ読んで全体としてどのような話題群が扱われているか調べ切れない場合。あるいは、工場内の製造工程で収集したセンサデータのように、そもそもそのままの姿では人間が理解しようとすること自体難しい場合などです。このような場合に潜在変数を使ったデータ分析を適用できます。私が研究で主に扱っているトピックモデルもその一例です。データについて知りたいことを、値の分からない変数と置いてしまい、その変数を部品にしてデータのモデルを作ります。そして、手元にあるデータができるだけうまく再構成されるようにモデルを“賢く”することで、潜在変数の値を推定します。
トピックモデルを使った分析では、個々の文書においてどのトピック(話題)がどのくらい重点的に扱われているかを潜在変数で表します。例えば、100個のトピックを見つけたいとします。このとき、個々の文書について100個の潜在変数を用意します。これらの変数は、各文書で100個のトピックそれぞれが扱われる確率を表します。さらに、それぞれのトピックについて、語彙数と同じ数の潜在変数を用意します。これらの変数は、それぞれのトピックを扱うときにどの単語がどのくらいの確率で使われるかを表します。そして、これら二つのタイプの潜在変数の値を、手元にある文書データができるだけうまく再構成されるように推定します。その結果、例えば、あるトピックで「リンク」「回転」「ルッツ」のような単語の確率が高ければ、フィギュアスケートに関係するトピックだと分かります。そしてこのトピックの確率が高い文書を探せば、フィギュアスケートについて書かれた文書が集まるでしょう。
最近では、トピックモデルと深層学習を組み合わせたデータ分析(変分オートエンコーダと呼ばれる手法を使います)にも取り組んでいますが…続きはまた、いずれ。
一方、私が主に取り組みたいデータ分析は、手元にあるデータ自体を良く知ろうとする分析です。
予測のためのデータ分析では、教師あり学習という種類の機械学習の手法がよく使われます。これは、手元にあるデータをモデルへ入力したときにどのような出力が得られると望ましいかを人間が計算機に教え、その通りに出力するようモデルを“賢く”させる手法です。しかし、人間が計算機に教えられるほどデータについてよく分かっていないこともあります。例えば、文書データであれば、あまりに文書数が多いため、一つ一つ読んで全体としてどのような話題群が扱われているか調べ切れない場合。あるいは、工場内の製造工程で収集したセンサデータのように、そもそもそのままの姿では人間が理解しようとすること自体難しい場合などです。このような場合に潜在変数を使ったデータ分析を適用できます。私が研究で主に扱っているトピックモデルもその一例です。データについて知りたいことを、値の分からない変数と置いてしまい、その変数を部品にしてデータのモデルを作ります。そして、手元にあるデータができるだけうまく再構成されるようにモデルを“賢く”することで、潜在変数の値を推定します。
トピックモデルを使った分析では、個々の文書においてどのトピック(話題)がどのくらい重点的に扱われているかを潜在変数で表します。例えば、100個のトピックを見つけたいとします。このとき、個々の文書について100個の潜在変数を用意します。これらの変数は、各文書で100個のトピックそれぞれが扱われる確率を表します。さらに、それぞれのトピックについて、語彙数と同じ数の潜在変数を用意します。これらの変数は、それぞれのトピックを扱うときにどの単語がどのくらいの確率で使われるかを表します。そして、これら二つのタイプの潜在変数の値を、手元にある文書データができるだけうまく再構成されるように推定します。その結果、例えば、あるトピックで「リンク」「回転」「ルッツ」のような単語の確率が高ければ、フィギュアスケートに関係するトピックだと分かります。そしてこのトピックの確率が高い文書を探せば、フィギュアスケートについて書かれた文書が集まるでしょう。
最近では、トピックモデルと深層学習を組み合わせたデータ分析(変分オートエンコーダと呼ばれる手法を使います)にも取り組んでいますが…続きはまた、いずれ。